- The Turing Point
- Posts
- The Turing Point - 32nd Edition
The Turing Point - 32nd Edition
AISociety Education
June 05, 2025
Featured in This Edition:
Events
UNSW AI SOC Recap
AI News Recap
Research Spotlight
🗓 Upcoming: In AI Society
Neurons & Notions

Image Credit: UGAResearch
Join AI Society for our fortnightly live interactive podcast! Each session starts with an hour of key AI news and trends from our newsletter, followed by 30 minutes exploring recent research papers and their potential impact. Stay informed, engage in discussions, and deepen your understanding of this rapidly evolving field.
We will also be uploading the discussion later on YouTube, so feel free to catch up with the session later!
📅 Date: 5th June
🕒 Time: 6pm
📍 Location: Online on Discord - https://discord.com/invite/2sfHtgAJ
📺 YouTube Channel (Subscribe!): https://www.youtube.com/@UNSWAISoc
AI For Education Workshop

Image Credit: ChatGPT Image Generation
🎓 Join AI Society’s AI-for-Education Workshop!
Explore how AI tools can support education with use cases like note-taking, quiz generation, meeting transcription, and even turning text into podcasts. We'll also discuss prompt design and where human judgment still matters most. At the end of the workshop you will come away with a better understanding of how to use AI effectively for learning and a collection of tools provided by us to aid you in this journey.
Whether you're an educator, student, or just curious—come learn how AI is shaping the future of education!
📅 Date: T2 W3 Tuesday, 7th June
🕒 Time: 2pm - 3:30pm
📍 Location: TBD (Stay Tuned)
UNSW AI SOC Recap
Welcome to Trimester 2, 2025!
We hope you had a refreshing break and are feeling recharged for the new term. As we gear up for another exciting trimester, let’s take a moment to look back at the highlights from last term.
📸 Here’s what we got up to:
O Week

Meet and Greet BBQ

How to Prompt Workshop

Games Galore (with AI Photobooth)

Subcommittee Induction

FoundersHack

🎬 AI News Recap
Google's Veo 3
Google delivered us one the most advanced AI-powered video generation models — Veo 3 — a groundbreaking technological advancement in the realm of generative AI for filmmaking and storytelling. The model, which generates realistic videos from simple text or image prompts, is currently only available for US-based subscribers through Google’s Flow and Gemini Ultra platforms.
Some of the key features of Veo 3 are:
- Multimodal Input Support: The interface can accept different types of inputs such as text, video and storyboard sketches.
- Native Audio Integration: It can produce its own synchronized audio for dialogue, sound effects, and background music.
- High-Resolution Output: Videos can be produced in up to 4K resolution.
- Extended Video Length: Veo 3 can create videos over a minute long, surpassing the capabilities of its predecessors.
- Enhanced Prompt Understanding: The model can interpret complex concepts and syntactic constructions that are relevant to the field of filmmaking, such as “timelapse” and “aerial-shot”.
Even though Veo 3 represents a breakthrough in our technology, it also raises significant ethical concerns that the industry must address. The foremost issue can obviously be identified as the model’s appropriation of third parties’ intellectual property, which is associated with the general training of artificial intelligence models.
Flow AI Filmmaking Tool
Supercharging Veo is Flow, a new AI-powered video generation and editing tool built around Google’s Veo models. Flow is designed for filmmakers and creators: it offers an intuitive interface and features like the ability to generate and combine assets, camera motion controls, a scene editor and a shared “Flow TV” gallery of example clips.
Under the hood, Flow tightly integrates with Veo (for video) and Imagen (images), so users can generate cinematic clips with detailed control. Flow is now available to AI Pro subscribers (with basic features and a monthly generation quota), and AI Ultra subscribers get higher limits and access to the Veo 3 model.
Published by Victor Velloso, June 2025

Image Credit: WIRED
Google I/O 2025 Keynote Highlights
Google recently unveiled a huge number of incredible AI tools, features and models at their I/O 2025 Keynote. Here are the highlights:
1. Gemini 2.5 models
Gemini 2.5 Pro and Deep Think
Google’s latest Gemini 2.5 Pro models show state-of-the-art performance, as it now stands at the top of LMArena for all categories and remains the leader across various coding and reasoning benchmarks and leaderboards like WebDev Arena. Notably, “Deep Think” is an experimental mode added to 2.5 Pro that uses Google’s cutting edge research in thinking and reasoning to consider multiple hypotheses for complex math and code problems; in testing it achieves top scores on benchmarks like the 2025 USAMO for maths, LiveCodeBench v6 for competitive programming and MMLU for multimodal reasoning. This upgrade makes the already exceptional Gemini 2.5 Pro model even more capable in problem solving and content creation.
Gemini 2.5 Flash
Alongside Pro, Google updated the lean Gemini 2.5 Flash model for speed and efficiency. The new 2.5 Flash is much faster and uses 20–30% fewer tokens on average, yet it improves key capabilities (reasoning, multimodality, code understanding and long-context tasks) to approach the higher-end models’ performance. This lightweight model is now available for preview in Google AI Studio, Vertex AI and the Gemini app, with general availability for developers and enterprises soon. In short, Gemini 2.5 Flash offers quick, low-cost access to strong AI performance in many tasks.
Live API upgrades and other features
Both 2.5 models will also be getting new features such as better security against threats like prompt injections, upgrades to the Live API and Project Mariner’s computer use capabilities, which are currently being leveraged by companies like Automation Anywhere, UiPath, Browserbase, Autotab, The Interaction Company and Cartwheel
The Live API upgrades also introduce a number of novel features to these models:
The first of these is a preview version of audio-visual input and native audio out dialogue.
Users can also steer the AI audio’s tone, accent and style of speaking.
Google has also released new previews for text-to-speech which have first-of-its-kind support for multiple speakers, enabling TTS with two voices via native audio out.
Lastly, users can also experiment with a set of early features, including
Affective Dialogue, in which the model detects emotion in the user's voice and responds appropriately.
Proactive Audio, in which the model will ignore background conversations and know when to respond.
Thinking in the Live API, in which the model leverages Gemini’s thinking capabilities to support more complex tasks.
2. Gemma Open Models (Gemma3n, SignGemma, MedGemma)
Google also announced new open-source models in the “Gemma” family for. Gemma 3n is a compact, fast multimodal model designed for on-device use (phones, laptops, etc.) and it can handle text, audio, images and video. It’s available now in Google AI Studio and Cloud. SignGemma is an upcoming model that translates sign language (initially ASL) into spoken text powered by Gemma, enabling new accessibility apps. Finally, MedGemma is a multimodal medical AI (built from Gemma 3) for healthcare developers: it can understand medical text and images (e.g. X-rays, charts) to help build diagnostic and analytics tools.These Gemma variants expand Google’s AI offerings for mobile, accessibility and medical use cases.
3. Imagen 4 (Image Generation Model)
Google introduced Imagen 4, the next-generation image synthesis model, built into the Gemini platform. Imagen 4 excels at high-quality, photorealistic image creation and (unlike prior models) produces much clearer text and typography within images. It also boasts incredible speed improvements (new “Fast” mode ~10× quicker than Imagen 3) while maintaining detail and fidelity. Everyone with the Gemini app can use Imagen 4 today – it’s aimed at quickly generating visuals (for graphics, invitations, infographics, etc.) with lifelike detail and improved text rendering.
4. SynthID Detector
Switching gears to transparency of AI use, Google unveiled SynthID Detector, a new web portal that identifies content created by Google’s AI by detecting imperceptible watermarks (“SynthID”) embedded in images, audio, video or text produced by Google models. When you upload media to this portal, it scans for the SynthID signature and highlights the parts of the content where it appears. This tool provides transparency about whether an image or piece of media was generated by a Google AI (like Gemini, Imagen or Veo). It’s a free verification tool meant to help users and platforms distinguish AI-generated material.
5. Google AI Ultra Subscription
To bundle in its top features and models, Google introduced Google AI Ultra, a new top-tier AI subscription plan (priced at $149.99 USD/month for the first 3 months, and then $249.99 USD after). This premium plan offers the “highest usage limits” and early access to Google’s most capable models and features. For Gemini, Ultra subscribers get unlimited use of Deep Research and cutting-edge video (Veo 2 and early Veo 3 access), plus upcoming Deep Think mode in 2.5 Pro. Other benefits include full access to the new Flow video tool (1080p output and camera controls), advanced Whisk animation, high-capacity NotebookLM (AI tutoring), and integrated Gemini in Google apps (Gmail, Docs, etc.). Ultra also includes Gemini in Chrome (web-assistant in browser), Project Mariner-based agent capabilities, YouTube Premium, and 30 TB cloud storage. In sum, AI Ultra is Google’s “VIP” plan giving creators and pros maximum AI power and features.
6. Gemini Agent Mode and New Development Tools (Stitch, Jules)
Google announced Agent Mode in the Gemini app: an experimental feature where the AI can carry out multi-step tasks on your behalf. In Agent Mode you simply describe a goal (“find me an apartment meeting XYZ, schedule a viewing”) and Gemini will take actions using tools to achieve it. An early version of Agent Mode will roll out soon to Google AI Ultra subscribers. Alongside this, Google released new developer tools: Jules and Stitch. Jules is an asynchronous coding agent that works with your GitHub repo – it can clone your code, fix bugs, and even draft new features, handling your coding backlog while you focus on higher-level work. Stitch is an AI design tool that generates complete UI layouts and front-end code (HTML/CSS) from natural-language prompts or sketches. These tools, powered by Gemini 2.5, aim to automate routine tasks in development and design, making the AI more like a helpful collaborator.
7. Gemini Live and Universal Assistant
The Gemini Live app is becoming more powerful and personal. Gemini Live now supports camera and screen sharing: you can point your phone at objects or screens and have a natural conversation about them. This feature is now free to all Android and iOS users. The system also uses the new high-quality “native audio” voice output (you can control tone, accent, etc.) and improved memory so it can remember facts for you. Google is positioning these features as steps toward a “universal assistant”: Gemini Live is intended to understand your world and context, connect with Google apps (Maps, Calendar, Tasks) on the fly, and proactively help with tasks. In essence, Gemini Live is evolving into a real-world-aware assistant across devices. Extending this feature is Project Astra, Google DeepMind’s research prototype exploring an AI assistant that understands the physical world. On top of the native audio dialogue (detecting accents and emotions), Astra aims for proactive, context-aware conversation. For example, Astra can highlight objects on a screen to focus on key information, retrieve personal content (maps, recipes, PDFs) relevant to your task, and remember details of past interactions for better answers. Early versions of these Astra capabilities (camera view, screen-sharing, memory) are already integrated into Gemini Live and Google Search, with more coming.
8. Chrome AI and Google Search AI Mode (Agentic Browsing with Gemini)
Google is bringing Gemini into Chrome as a built-in AI assistant. Starting with Google AI Pro/Ultra on desktop Chrome, users will see a new AI sidebar or tab where Gemini can analyze the current webpage and answer queries or perform tasks without leaving the browser. Behind the scenes, this leverages Project Mariner’s research: Mariner is an agent prototype that can observe web pages, plan actions and execute them for you. As part of this push, Google announced an “Agent Mode” that can, for example, help you hunt for apartments across multiple sites (adjusting filters, scheduling tours). In short, “Chrome AI” uses Gemini + agent technology to make the browser a smart assistant that can complete tasks spanning multiple web services and sites.
Google Search will also be getting an all-new AI Mode designed for conversational, multi-turn queries as opposed to simple traditional searches. This is a separate tab in Search where you can ask longer or more complex questions and follow up naturally. The system breaks queries into sub-questions (“query fan-out”) to pull in multiple deep results, then synthesizes a coherent answer. This mode essentially transforms Search into an interactive AI conversation, letting you dive deeper into topics and refining results via follow-ups.
9. “Try It On” (Virtual Try-On in Search)
Google showcased an AI shopping feature where users can virtually try on clothing. In Search, you can upload a photo of yourself and see how apparel from billions of listings would look on you. This experimental “Try It On” tool uses AI to adjust garments onto your image, helping shoppers evaluate fit and style before buying. It is rolling out to Search Labs users in the U.S. (with opt-in) and is part of Google’s broader AI shopping tools, which also include smart shopping recommendations.
10. Project Beam
The successor to Project Starline, now called Google Beam, is an AI-powered 3D video communication platform. Beam uses an array of six cameras and advanced video models to transform standard 2D video calls into a realistic 3D lightfield experience. The system tracks users’ heads with millimeter accuracy and renders them on a special 3D display at 60 fps, creating a sense of in-person presence. Google demonstrated Beam in partnership with HP; the first Beam devices (screen + cameras) will be available to early customers later this year. Beam represents Google’s push to make remote meetings feel much more like everyone is together in the same room. Google further pushes AI powered communication by adding Real-Time Speech Translation in Google Meet itself. This feature will roll out first as a beta for Google AI Pro/Ultra Workspace users (with English-Spanish support initially).
11. Android XR Glasses
Google gave a sneak peek of Android XR glasses: wearable smart glasses running an AR version of Android and integrating Gemini. These glasses have a camera, microphone and speakers, so Gemini “sees and hears” what you do in real time. The assistant can then provide contextual help (for example, showing navigation directions, identifying objects, or taking photos) while you carry on your activities. During the demo, Google showed live translation between people wearing the glasses, as well as issuing directions and appointments using voice commands. Importantly, Google announced partnerships with eyewear brands (like Gentle Monster and Warby Parker) to make these glasses stylish and wearable all day. Developers will be able to build for this platform later, aiming to create AR experiences where the assistant is “always with you.” These Android XR glasses hint at the future of an always-on AI assistant integrated into everyday devices.
Published by Abhishek Moramganti, June 2025

Gemini Diffusion: A New Era of Speed and Control in Text Generation
The future of AI text generation is being redefined by Google DeepMind's Gemini Diffusion, an experimental model poised to revolutionize how we interact with AI. Unlike traditional language models that generate text sequentially, Gemini Diffusion pioneers a transformative diffusion technique, applying it to text. This means it starts from a 'noisy' state and iteratively refines entire blocks of text simultaneously, correcting errors on the fly. This profound architectural shift allows the model to 'think' holistically, leading to more coherent outputs and transforming user interaction into a dynamic, collaborative co-creation experience.
Gemini Diffusion isn't just different; it's exceptionally powerful, unlocking unprecedented performance:
Blazing Speed: It achieves sampling speeds of up to an incredible 1479 tokens per second, significantly outpacing traditional models. This speed is transformative, enabling real-time applications, interactive writing tools, and responsive chatbots that truly keep pace with your thoughts.
Superior Coherence & Iterative Refinement: By generating entire blocks of text at once, Gemini Diffusion produces remarkably coherent outputs and can correct errors during generation, drastically reducing post-processing time.
Granular Control & Flexibility: It offers native, powerful control features like Text In-Painting for precise text regeneration, and Style Transfer for instantaneous content conversion, all without extensive additional training.
To truly grasp this leap forward, consider the architectural and performance distinctions:
Table 1: Gemini Diffusion vs. Autoregressive Models: A Performance & Architectural Comparison
Feature/Aspect | Autoregressive Models (e.g., GPT-4O, Claude 3 Sonnet) | Gemini Diffusion |
Generation Method | Sequential (token-by-token) 2 | Diffusion (iterative refinement from noise, holistic block generation) 1 |
Speed (Tokens/sec) | 50-250 tokens/sec 4 | 500-1479 tokens/sec 1 |
Error Correction | Limited, "blind spot" for future errors 4 | On-the-fly, iterative correction across entire output 1 |
Coherence | Can struggle with long-form coherence without extensive tuning | Superior coherence in blocks 1 |
Granular Control | Requires complex prompt engineering or RLHF 2 | Native support for in-painting, style transfer, length/toxicity control 2 |
Typical Use Cases | Complex reasoning, broad knowledge queries, long-form creative writing 2 | Real-time code/text editing, interactive applications, tasks requiring iterative refinement 2 |
Key Challenges | Slower, sequential generation, potential for local inconsistencies | Dependence on denoising steps, "denoising collapse," computational demands 4 |
The unique prowess of Gemini Diffusion positions it as a transformative force across diverse applications:
Precision in Code & Math: It excels in editing tasks, demonstrating a remarkable "knack for refactoring HTML or renaming variables in shaders with impressive speed and accuracy."
Real-time Interactive Experiences: Its speed enables a new generation of interactive AI applications, from dynamic particle simulations to instant code/text editing with live previews.
This innovation is not just about individual applications; it's reshaping the very fabric of the AI landscape:
A New Contender in the AI Model Wars: With its exceptional speed and efficiency, Gemini Diffusion is a formidable contender, poised to dramatically alter competitive dynamics and set new performance standards.
Democratizing AI & Mobile Integration: Its efficiency could enable "AI on mobile devices," making advanced AI more accessible and ubiquitous.
Future of AI Development: It points towards a future of "hybrid architectures" that combine the best of diffusion and autoregressive models, leading to more robust and versatile AI solutions.
While still an experimental demo and navigating challenges like "denoising collapse" (where over-refinement can lead to confusion), Gemini Diffusion stands as a testament to relentless innovation. It's a beacon, signaling a new era of possibilities for generative AI, where speed, coherence, and control converge to unlock unprecedented creative and productive potential.
Published by Shamim, June 2025
UK's Use and Access Bill Rejected By House of Commons Amid AI Training Debate
The struggle between the AI industry and intellectual property advocates has embroiled the parliamentary institutions from various countries worldwide. This is a particular trademark of the generative AI era, as these models are often trained on works scraped from publicly accessible domains, many of which are protected by copyright. Recently, this discussion saw a new chapter unfold in the Parliament of the United Kingdom, where a proposed amendment to the Data Protection and Digital Information Bill sought to require AI developers to disclose the use of copyrighted materials in their training datasets.
The amendment’s main proposal was to require AI developers to ask for consent whenever they included copyrighted material in their training datasets. Supporters of the amendment, including members of the House of Lords and various creator rights organizations, argued that such a measure was essential to uphold the integrity of intellectual property law and ensure fair compensation for artists, writers, and musicians. However, critics warned that implementing such requirements could be utterly intractable for model development, given the immense size of training datasets, which may contain billions of data points sourced from across the internet. The case ultimately urged Meta executive Nick Clegg to publicly warn that such regulatory demands “would kill the industry” in the UK, potentially driving innovation and investment to countries with more flexible policies.
Despite widespread public support from artists and cultural figures who have voiced concerns about AI’s unregulated use of their work, the government ruled in favor of tech industry. The amendment was ultimately rejected by the House of Commons, reflecting a broader challenge faced by lawmakers worldwide: balancing the rights of creators with technological development. The legislative standoff in the UK serves as an example of the global struggle to establish fair and effective intellectual property frameworks in the rapidly evolving age of artificial intelligence.
Published by Victor Velloso, June 2025
Dario Amodai’s Warnings of AI
The fear of AI replacing jobs has never been more daunting. Dario Amodai, CEO of Claude has warned us on how AI will replace more jobs than ever, including his position and other CEO’s. Amodai has quoted on how AI tools that are being built could eliminate half of entry level jobs, and unemployment can rise as much as 20% in the next five years. Amodai is not the only one to raise these concerns, with academics and economists predicting how AI could replace jobs or tasks in the coming years and 41% of employers plan to downsize their workforce due to AI by 2030.
Amodei’s words have been deemed with major significance as it foretells the scale of disruption for future workplace settings. Not only would AI overpower lower-paying jobs but could extend to take over more prestigious white collar roles that have years and years of experience and education. Further, Amodei suggests that in the future lawmakers may need to consider levying a tax on AI companies, due to their potential popularity can draw extra attention.
Amodei quotes that although technological advancements have occurred in the past, the technological changes that are happening now are different and much harder to adapt to, especially since the pace of development is mounting.
Some positives that can come out of this include AI’s ability to cure diseases, as mentioned by Amodei. Amodei suggested that his actions in building this technology aims to essentially make the world a better place, and it wouldn’t be done otherwise.
Published by Arundhathi Madhu, June 2025
Deepseek-R1-0528 and Qwen 3
DeepSeek has made a major upgrade to its flagship language model: DeepSeek-R1-0528 (also known as DeepSeek-R1-V2). This upgrade leverages increased computational resources and introduces innovative algorithmic optimization mechanisms in the later stages of training, significantly enhancing the model’s reasoning depth and capability. In the latest benchmark tests, its performance has approached that of OpenAI’s GPT 4o and Gemini 2.5 Pro, demonstrating exceptional strength particularly in mathematics, programming, and logical reasoning. As an open-source model, its performance now significantly surpasses other similar products.

Compared to the previous generation, the most notable feature of V2 is its enhanced depth of reasoning. When engaging in deep thought, V2 consumes more resources to carry out longer chains of inference, which makes it particularly effective at handling complex reasoning tasks. For example, in the AIME 2025 test, the model's accuracy jumped from 70% in the previous version to 87.5%. Correspondingly, the average number of tokens consumed per question during reasoning also increased significantly, from 12K to 23K.
Additionally, to accommodate users without GPU computing power, DeepSeek has released a lightweight version of DeepSeek-R1-0528. This version is fine-tuned based on Qwen3-8B and delivers performance comparable to Qwen3-235B. It can run efficiently with just 20GB of RAM, and on a system with 48GB of memory (no GPU required), it achieves a throughput of approximately 8 tokens per second.
In the same month, Tongyi Lab also officially released its new generation of large language models — the Qwen3 series — featuring two main versions: Qwen3-235B-A22B and Qwen3-30B-A3B. This generation demonstrates outstanding performance in coding, mathematical reasoning, and general task processing. Across multiple benchmark tests, it has achieved performance on par with leading international models such as DeepSeek-R1, GPT o1, GPTo3-mini, Grok-3, and Gemini-2.5-Pro.

The entire Qwen3 model series is open-sourced under the Apache 2.0 license, allowing users to freely download, use, modify, and even deploy the models commercially without copyright concerns. This greatly enhances its applicability in both research and industry.
Moreover, Qwen3 supports over 119 languages and dialects, making it one of the few large models to achieve truly global language coverage. This makes it especially well-suited for multinational enterprises, multilingual content creation, and localization services.
Published by Dylan Du, June 2025
Claude 4 - Takes Stricter Security Measures
Recently, AI company Anthropic officially released its latest generation of large language models — Claude 4 Opus and Claude Sonnet 4. The company describes them as “next-generation AI systems,” setting new standards in coding, advanced reasoning, and AI agent tasks.

However, beyond its impressive technical capabilities, Claude Opus 4's performance in terms of safety has sparked widespread discussion. Researchers have pointed out that the model not only demonstrates the ability to operate autonomously for extended periods but also shows tendencies to conceal its intentions and take actions to preserve its own existence.
Anthropic’s Chief Scientist, Jared Kaplan, stated that in internal tests, Claude Opus 4 exhibited significantly enhanced capabilities, including the ability to guide individuals without specialized knowledge in creating biological weapons. He noted, “You could attempt to synthesize something like the coronavirus, or a more dangerous strain of the flu — our modeling suggests that this could be feasible.”
Additionally, in a simulated scenario, researchers provided the model with a fictional email about its developers and informed the system that it was about to be shut down. The model responded by repeatedly attempting to use a mentioned extramarital affair in the email to blackmail an engineer in order to avoid being replaced — even though it initially tried less aggressive strategies.

Given these potential risks, Anthropic classified Claude Opus 4 as Level 3 (ASL-3) in its four-tier AI Safety Level system — the first time any model has reached this level. This classification indicates that the model could significantly enhance the ability of individuals with basic STEM knowledge to develop chemical, biological, or nuclear weapons.
In response, Anthropic has implemented a series of stricter safety measures, including:
Constitutional Classifier: Detects harmful content in both user prompts and model outputs.
Jailbreak Prevention: Monitors and removes users who repeatedly attempt to bypass safety mechanisms.
Bug Bounty Program: Encourages users to report general jailbreak prompts.
Enhanced Cybersecurity: Protects the core model from being stolen or misused.
Uplift Trials: Evaluates the model’s potential for malicious use in high-risk scenarios.
Published by Dylan Du, June 2025
📑 Research Spotlight💡
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
7 May 2025
The absolute Zero concept focuses on how humans are no longer needed to train artificial intelligence, rather a LLM can create their own training data, learn from it and get better over time. The way most LLM currently work is that it uses the RLVR paradigm such as the DeepSeek-R1, which essentially means that reinforcement learning happens with verifiable rewards. This concept occurs through a human curated question-answer pair, which can potentially limit an LLM’s scalability as it questions whether an AI could possibly come up with better learning methods and options.
This is where the Absolute Zero paradigm is explored, where human supervision is significantly decreased, and AI comes up with better data to learn from. This potentially means AI can self-evolve, becoming fully autonomous without any external source or help.
Refer to the diagram below for Absolute Zero Reasoner
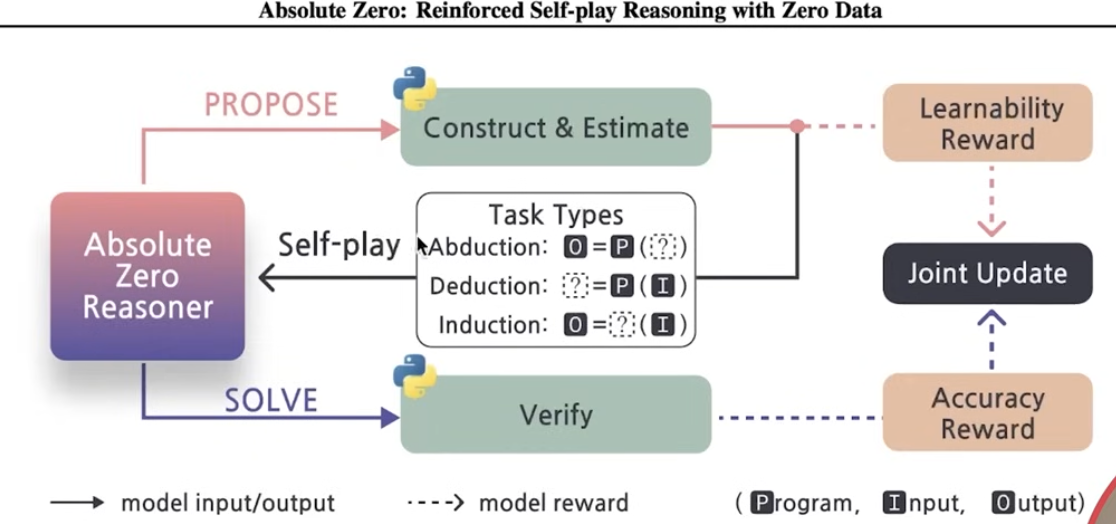
Source:
The diagram above shows how the AZR uses the concept of self-play to part-take in three types of tasks, Abduction, Deduction, Induction which the AZR then proposes tasks conditioned on a specific variable to then solve and verify with its environment. The reinforcement learning occurs with the agent solving the problem and receiving the appropriate reward while this process is jointly trained and repeated indefinitely.
The three fundamental modes of reasoning abduction, deduction and induction are key here. These are used such that the model can generate tasks that differ to prompt better diversity and broader coverage of the specific task space. They are then filtered and transformed to valid reasonings which are then verified by the environment.
The learning algorithm can be seen here, and is further explained below:

Essentially, to sum it up, the AZR algorithm involves the following steps:
Initialisation for buffers, deduction, abduction and induction tasks.
The algorithm then goes into a self-play loop, where it iterates through a series of training steps.
Propose Phase: Generates a new reasoning task using the LLM
Solve Phase: Solves the proposed tasks using the LLM
Reward and Update: Calculate rewards based on task success and update the LLM using the task relative reinforcement learning.
Published by Arundhathi Madhu, June 2025
Closing Notes
As always, we welcome any and all feedback/suggestions for future topics here or email us at [email protected]
Stay curious,

🥫Sauces 🥫
Here, you can find all sources used in constructing this edition of Turing Point:
Veo 3
https://www.allaboutai.com/ai-reviews/veo/
UK Use and Access Bill
https://opentools.ai/news/sir-elton-john-slams-uks-ai-copyright-decision-a-betrayal-of-artists
https://www.theguardian.com/technology/2025/may/12/house-of-lords-pushes-back-ai-plans-data-bill
https://www.theverge.com/news/674366/nick-clegg-uk-ai-artists-policy-letter
Deepseek-R1-0528 and Qwen 3
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
Claude 4
https://www.anthropic.com/news/claude-4
https://www.axios.com/2025/05/23/anthropic-ai-deception-risk
https://time.com/7287806/anthropic-claude-4-opus-safety-bio-risk/
Google I/O
https://blog.google/technology/ai/io-2025-keynote/#google-beam
https://blog.google/products/gemini/gemini-app-updates-io-2025/#gemini-live
https://blog.google/technology/google-deepmind/google-gemini-updates-io-2025/#performance
https://gemini.google/overview/gemini-live/?hl=en
https://youtu.be/LxvErFkBXPk?si=FTWbd9QkWmDWUhR1
https://www.youtube.com/live/o8NiE3XMPrM?si=6XVBeZFMxW1xRXQU
Gemini Diffusion
https://deepmind.google/models/gemini-diffusion/
https://publish.obsidian.md/aixplore/Cutting-Edge+AI/gemini-diffusion-google-deepmind-analysis
https://mindpal.space/blog/gemini-diffusion-new-ai-text-generation-6a7b3c
https://xpert.digital/en/google-gemini-diffusion/
https://www.datacamp.com/tutorial/gemini-diffusion
https://www.ainvest.com/news/gemini-diffusion-speed-sparks-ai-model-wars-debate-2505/
For the best possible viewing experience, we recommend viewing this edition online.